
I dispositivi audio indossabili compatti, come ad esempio gli auricolari o gli ausili per l’udito, sono alimentati da System-on-Chip (SoC) basati su microcontrollore che, grazie al loro elevato grado d’integrazione, sono vere e proprie meraviglie tecnologiche. I SoC integrano capacità di calcolo per scopi generici e di elaborazione del segnale digitale (DSP) ad alte prestazioni, in grado di gestire funzioni audio importanti, come l’elaborazione codec, la riduzione del rumore, l’analisi FFT e la compressione, in combinazione con funzioni di rete Bluetooth, gestione della batteria e controllo del sistema. Questo livello d’integrazione non soltanto consente di abbattere il costo dei materiali ma permette anche ai costruttori di offrire audio di qualità superiore in formato ridotto e indossabile.
Eppure, le regole del gioco stanno per cambiare. L’ultima frontiera dell’audio indossabile, infatti, è l’intelligenza artificiale (AI). Integrando l’AI direttamente nel SoC, i costruttori possono ottimizzare sensibilmente le funzioni audio come la cancellazione del rumore e la cancellazione dell’eco, nonché introdurre funzioni avanzate, quali il riconoscimento vocale e l’elaborazione del linguaggio naturale (NLP) per l’individuazione di parole chiave (KWS).
Ad ogni modo, la sfida giace proprio nell’implementazione dell’AI senza compromettere la compattezza, l’efficienza energetica o il costo di questi dispositivi.
Il potere dell’AI nei dispositivi audio indossabili
Nell’AI si cela una potenziale rivoluzione del mercato dell’audio indossabile. La tradizionale cancellazione del rumore, che prende il nome di Active Noise Cancellation (ANC), si affida ad algoritmi fissi che trasformano costantemente i rumori ambientali ed emettono un impulso di fase opposta al fine di annullare il segnale del rumore ambientale: questo metodo consuma quantità notevoli di energia e con difficoltà si adatta agli ambienti variabili.
Al contrario, l’AI gestisce la cancellazione del rumore in modo diverso e senza consumare troppa energia. Analizzando il rumore ambientale e individuandone la singolare natura, l’AI può selezionare dinamicamente l’algoritmo più efficace di cancellazione del rumore, attingendo a una libreria di modelli pre-formati e adeguandosi all’ambiente circostante in tempo reale. Basata sull’AI, questa tecnologia non richiede l’ascolto attivo continuo dell’ambiente alla ricerca del rumore tramite diversi microfoni, e già questo si traduce in un risparmio energetico.
Diverse aziende rivestono già il ruolo di leader con software AI off-the-shelf per la cancellazione del rumore, offrendo funzioni avanzate di cancellazione del rumore o la cancellazione del rumore AI.
I vantaggi sono evidenti. La cancellazione AI-enhanced del rumore non soltanto si adatta con maggiore efficacia a condizioni aurali dinamiche, ma riduce sensibilmente anche il consumo energetico, attivando il campionamento periodico dei rumori. Quest’innovazione estende la durata della batteria dei dispositivi indossabili, assicurando un utilizzo prolungato senza rinunciare alle prestazioni.
L’integrazione dell’AI in altre funzioni DSP, ad esempio l’elaborazione vocale, la KWS e la cancellazione dell’eco, offre altresì vantaggi trasformativi simili.
Superare i limiti dei SoC tradizionali
Tentare di eseguire questo tipo di modello AI audio sui SoC DSP-rich tradizionali in uso nei dispositivi indossabili, tuttavia, si traduce spesso in prestazioni substandard. I DSP e le CPU come il core Arm Cortex-M7 sono ottimizzati per le operazioni sequenziali, rendendoli inadatti al calcolo altamente parallelizzato richiesto dalle reti neurali dell’AI. Questa mancata corrispondenza comporta un elevato consumo energetico e tempi di risposta lenti, specialmente in funzioni dove la reattività è importante, come la KWS.
La Figura 1 mostra la differenza sostanziale, in termini di prestazioni, tra una CPU standard e la combinazione di CPU e unità di elaborazione neurale (NPU), quando si eseguono comuni attività AI. Il confronto sottolinea l’esigenza di una NPU dedicata ottimizzata per attività AI, come il core NPU Arm Ethos che eccelle nei dispositivi AI edge, in virtù del suo bassissimo consumo energetico e dell’integrazione fluida con la famiglia di CPU Cortex-M (M55 e oltre).
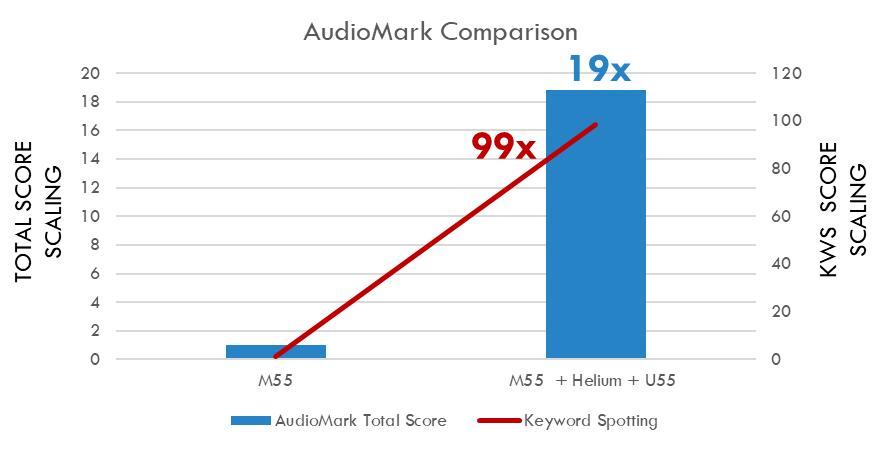
Fig. 1: Le prestazioni benchmark del MCU wireless Balletto di Alif Semiconductor con core Cortex-M55, estensione vettoriale Helium M e core NPU Ethos-U55. Confronto delle prestazioni per le funzioni comuni di elaborazione audio: soppressione del rumore, beamforming a due microfoni, cancellazione dell’eco e individuazione delle parole chiave
Progettare un’architettura dei SoC per l’eccellenza AI
L’ottimizzazione di un SoC audio wireless con capacità AI richiede molto di più che aggiungere soltanto una NPU. Per cogliere il pieno potenziale dell’AI e preservare l’efficienza energetica, il SoC deve essere equipaggiato con una grande memoria tightly coupled e la gestione avanzata dell’alimentazione che può disattivare selettivamente porzioni del MCU quando non in uso. Anche la scelta del core CPU si rivela decisiva. Ad esempio, con la sua estensione vettoriale M-profile (MVE) Arm Helium, il core Cortex-M55 offre migliorie notevoli delle funzioni machine learning (ML) e DSP, superando sul piano prestazionale persino il core Cortex-M7 high-end e offrendo prestazioni ML 4 volte superiori e DSP 3 volte migliori.
Le prestazioni AI traggono il vantaggio più significativo quando si aggiunge una NPU. La Figura 2 mostra i vantaggi prestazionali di un MCU Ensemble Alif che racchiude dual core Cortex-M55 con dual NPU Ethos-U55, sinonimo di risultati eccellenti nell’esecuzione di inferenze sui modelli ML, compresa una per KWS on-device nell’endpoint.
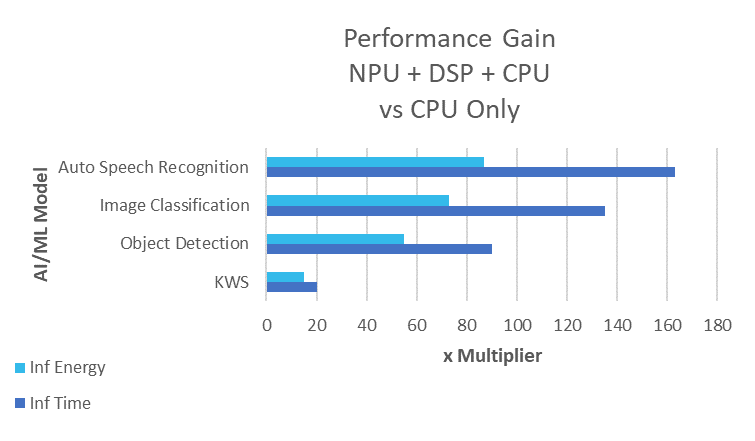
Fig. 2: Uplift delle prestazioni dovuto all’utilizzo di NPU del SoC e accelerazione matematica vettorizzata più la CPU rispetto al solo core CPU in tipiche funzioni AI edge
Nello specifico, per i costruttori di dispositivi audio wireless, il vantaggio di scegliere un SoC basato su Cortex-M55 con NPU Ethos si evince nei risultati dei test per il cruciale benchmark AudioMark, specificato da EEMBC. In conformità con EEMBC, “il benchmark AudioMark™ è il benchmark audio primo nel suo genere a integrare l’elaborazione avanzata del segnale, tipi di dati multipli e una rete neurale convoluzionale in un unico benchmark con un’impronta realistica del codice”.
Il benchmark si propone di misurare le prestazioni nelle funzioni AI, come la KWS, nonché funzioni tradizionali di elaborazione audio come il beamforming, la cancellazione dell’eco e del rumore. Come mostra la Figura 2, la combinazione di NPU Ethos-U55 e MVE Helium, che lavorano insieme al core Cortex-M55, offre un uplift sostanziale delle prestazioni benchmark a confronto con il Cortex-M55 che esegue l’inferenza da solo.
Pionieri dei SoC con ottimizzazione AI
Un esempio primario di quest’architettura ottimizzata con AI è il MCU Balletto B1 di Alif Semiconductor. Alloggiato in un involucro compatto, Balletto B1 integra una CPU Cortex-M55, una NPU Ethos-U55 e fino a 2 MB di SRAM tightly coupled. Il suo sottosistema radio a 2,4 GHz supporta Bluetooth Low Energy v5.3 e le reti 802.15.4, rendendolo una soluzione potente e al contempo efficiente per i dispositivi audio indossabili controllati dall’AI. Balletto B1 supera notevolmente le prestazioni dei core DSP attuali sia nelle attività AI sia nelle operazioni Bluetooth, introducendo un nuovo standard di settore.
Il futuro dell’audio indossabile
L’introduzione di MCU wireless con ottimizzazione AI, come Balletto B1, apre le porte a una nuova era dell’audio indossabile. Alla luce dell’aumento della domanda di capacità AI in dispositivi piccoli ed efficienti sul piano energetico, il mercato risponde con soluzioni innovative che consentono ai costruttori di sviluppare prodotti compatti e ad alte prestazioni con durata estesa della batteria.
L’integrazione AI nei SoC di audio indossabile non rappresenta soltanto un aggiornamento, bensì è una rivoluzione che promette di ridefinire l’esperienza di ascolto.
 A cura di Sree Durbha
A cura di Sree Durbha
Direttore Senior del Product Marketing, Alif Semiconductor























{kind=link}